Fair Evaluation
Lack of Fair Comparison Across Different Agents
Varied network topologies, fault sets, observability tools and evaluation metrics hinder the comparison of agentic troubleshooting strategies across the research community.
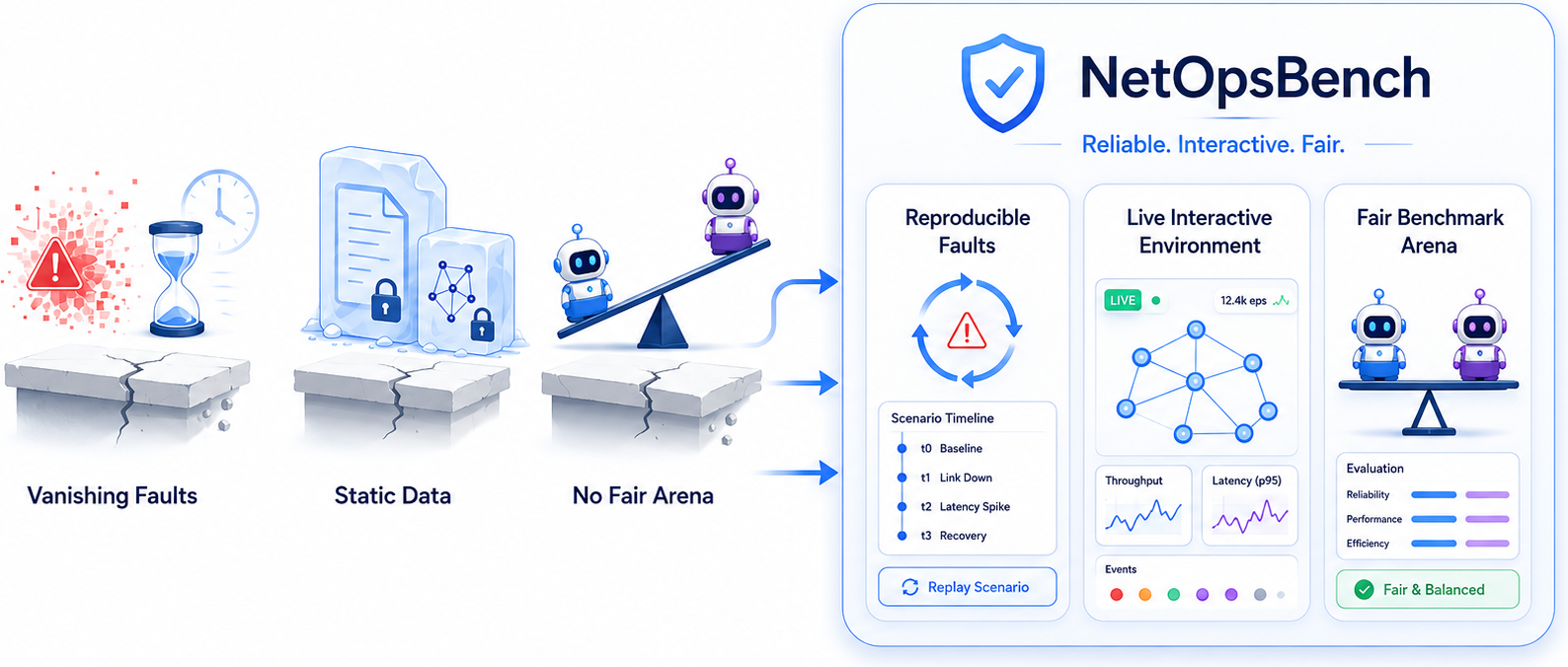
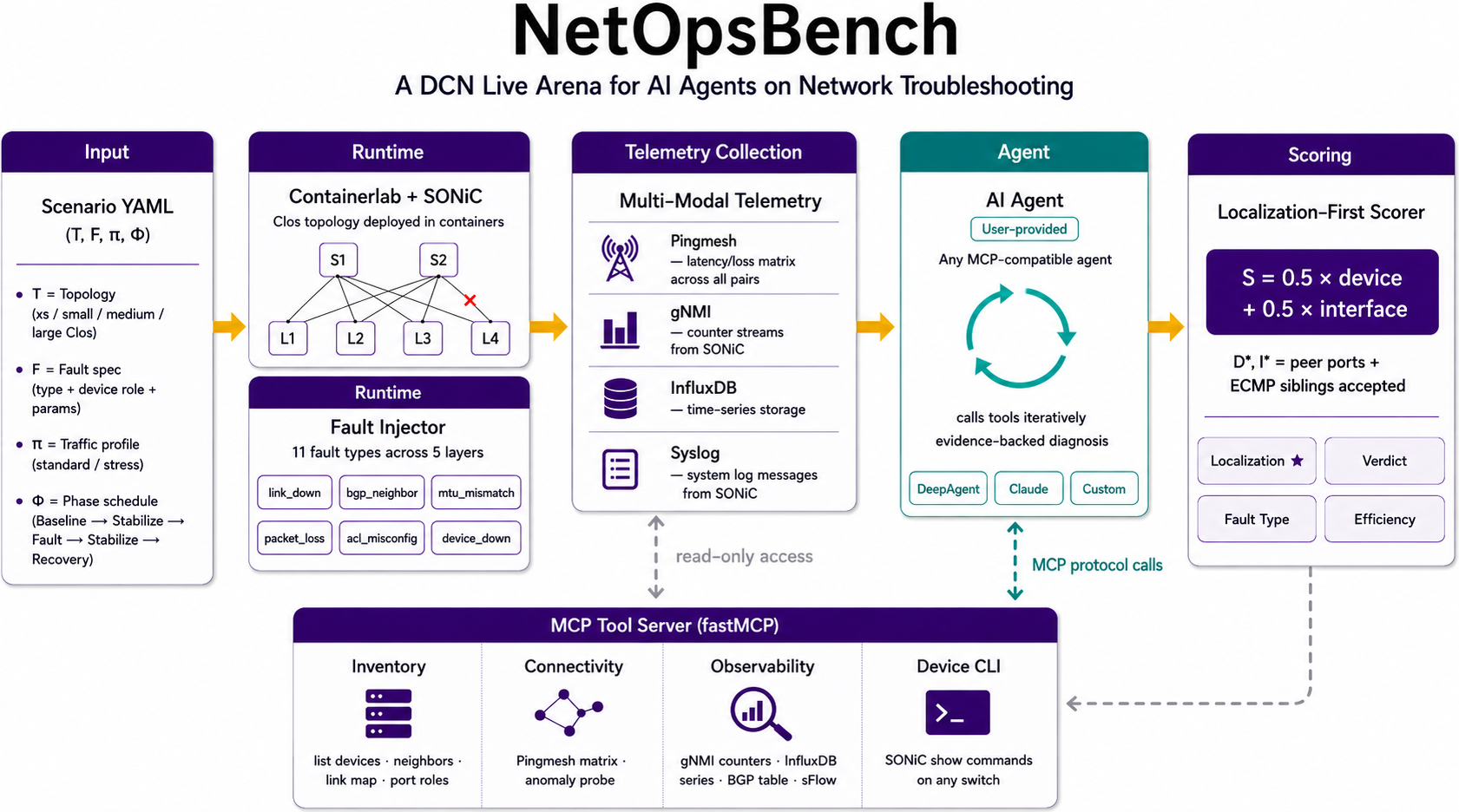
NetOpsBench evaluated agentic network troubleshooting in modern AI infrastructure. The platform supports the emulation of diverse live, interactive data-center network environments, injects controlled and reproducible faults, and evaluates custom agent strategies against ground truth.
According to the Broadcom 2026 State of Network Operations Report, 71% of large enterprises do not fully trust AI-based network operations, and only 27% have mature automation practices. The primary barrier is not insufficient agentic strategies, but the lack of reproducible, reliable benchmarks and evaluation environments to guide the iteration and validation of these strategies.
Varied network topologies, fault sets, observability tools and evaluation metrics hinder the comparison of agentic troubleshooting strategies across the research community.
Real network incidents cannot be reliably reproduced or labeled with consistent ground truth, slowing iterative improvement and evaluation of troubleshooting agents.
Static topology snapshots and logs cannot provide live probing and telemetry signals required by agents for diagnostic work.
NetOpsBench builds open, fair, and publicly available arenas where you can test your agentic strategies and obtain objective, reproducible performance results.
Supports emulation of mainstream data-center network live environments, including spine-leaf, fat-tree and rail-optimized topologies.
Pingmesh, BGP state, gNMI counters, switch CLI output, syslog, and Grafana-backed telemetry are available through runtime services and MCP tools.
Scenarios inject controlled faults and automatically trigger the diagnosis loop, giving each agent the same fault window, topology, and evidence surface.
Every diagnosis is automatically evaluated based on detection accuracy and operational efficiency, enabling fair comparisons between different strategies.
Start from a clean environment, run one scenario, then inspect generated artifacts and scores.
git clone https://github.com/NetX-lab/NetOpsBench.gitcd NetOpsBenchpython -m venv .venvsource .venv/bin/activatepip install -e ".[agent]"export OPENAI_API_KEY=...PYTHONPATH=. python examples/01_run_scenario.py --vendor openaiStart from the Quickstart, then swap in your own diagnose(context) implementation.
[1] Broadcom, 2026 State of Network Operations Report. Accessed May 2026. PDF.